DynamoDB Paper - a Teardown
·9 min read
If you've been living under a rock, here's a quick intro to DynamoDB. DynamoDB is one of the most popular databases being used today, known for its durability, availability and consistent performance.
In 2021, during Amazon's Prime Sale, DynamoDB handled a trillion calls in 66 hours, peaking at 89.2 million requests per second (!).
Let's see how this system was built.
During its early design phase, the DynamoDB team set a clear goal: Deliver consistent performance at scale with low, single-digit millisecond latency
To achieve this, they established 6 principles which shape this system's architecture.
- It is a fully managed cloud service: The user only has to care about read write APIs
- It employs a multi-tenant architecture: DynamoDB stores the data of multiple customers on the same machines, to ensure high resource utilisation.
- It achieves boundless scale for tables: There are no pre-defined limits on sizes for the amount of data a table can hold. The tables grow elastically to meet customer demand.
- It offers predictable performance: DynamoDB latencies are predictable no matter the size of the table. Tables with sizes ranging from a few megabytes to a hundreds terabytes will experience similar latencies owing to the distributed nature of the data.
- It is highly available: Data is replicated across multiple Availability Zones and automatically re-replicates in case of any node failures. DynamoDB offers an availability SLA of 99.99% for local and 99.999% for global tables.
- It supports flexible use-cases: DynamoDB tables don't have a fixed schema but instead allow a table entry to have any amount of attributes with any data type, including multi-values attributes.
Architecture
Primary keys
DynamoDB table is a collection of items. Each item is uniquely identified by its primary key. Primary key can consist of 2 parts:
- Partition key - Which tells DynamoDB which partition this key sits in.
- Sort key - This key is used to sort the items within the same partition.
While sort key is optional, partition key is mandatory. The primary key needs to be decided at the time of table creation.
Secondary Indexes
DynamoDB also supports secondary indexes to provide enhanced querying capabilities. A secondary index allows users to query the database with more user-defined keys, other than the primary key.
Partitions
A DynamoDB table is divided into multiple partitions to handle the throughput and storage requirements of the table. Each partition hosts a disjoint and contiguous part of the table's key-range.
Availability
Each partition has multiple replicas across multiple availability zones for high availability and durability. The replicas of a partition form a "replication group".
The replication group uses Multi-Paxos for leader election and consensus. Any replica can trigger a round of election. Once a replica is elected leader, it maintains its leadership until its leadership period expires. The leader of the group extends its leadership using a lease mechanism. If the leader of the group is failure detected (considered unhealthy or unavailable) by any of its peers, the peer can propose a new round of the election to elect itself as the new leader.
DynamoDB supports strongly and eventually consistent reads. Only the leader replica can serve strongly consistent reads, while eventually consistent reads are served by follower replicas.
A replication group consists of storage replicas that contain both WALs (Write ahead logs) and B Tree that stores the key value data. These replication groups also contain replicas that only store WALs. These replicas are called log replicas.
When writes come to the leader,
- An entry is made in the WAL
- The update is sent to the follower replicas
- Once acknowledged by a majority, an OK response is returned.
How does DynamoDB handle Hot partitions?
A hot-partition is observed when one partition of a table receives significantly more requests than other partitions. A partition in DynamoDB has an upper limit of 3000 RCUs and 1000 WCUs. If either of these limits get breached, DynamoDB automatically splits the partition into two. This is how it becomes truly elastic and scalable.
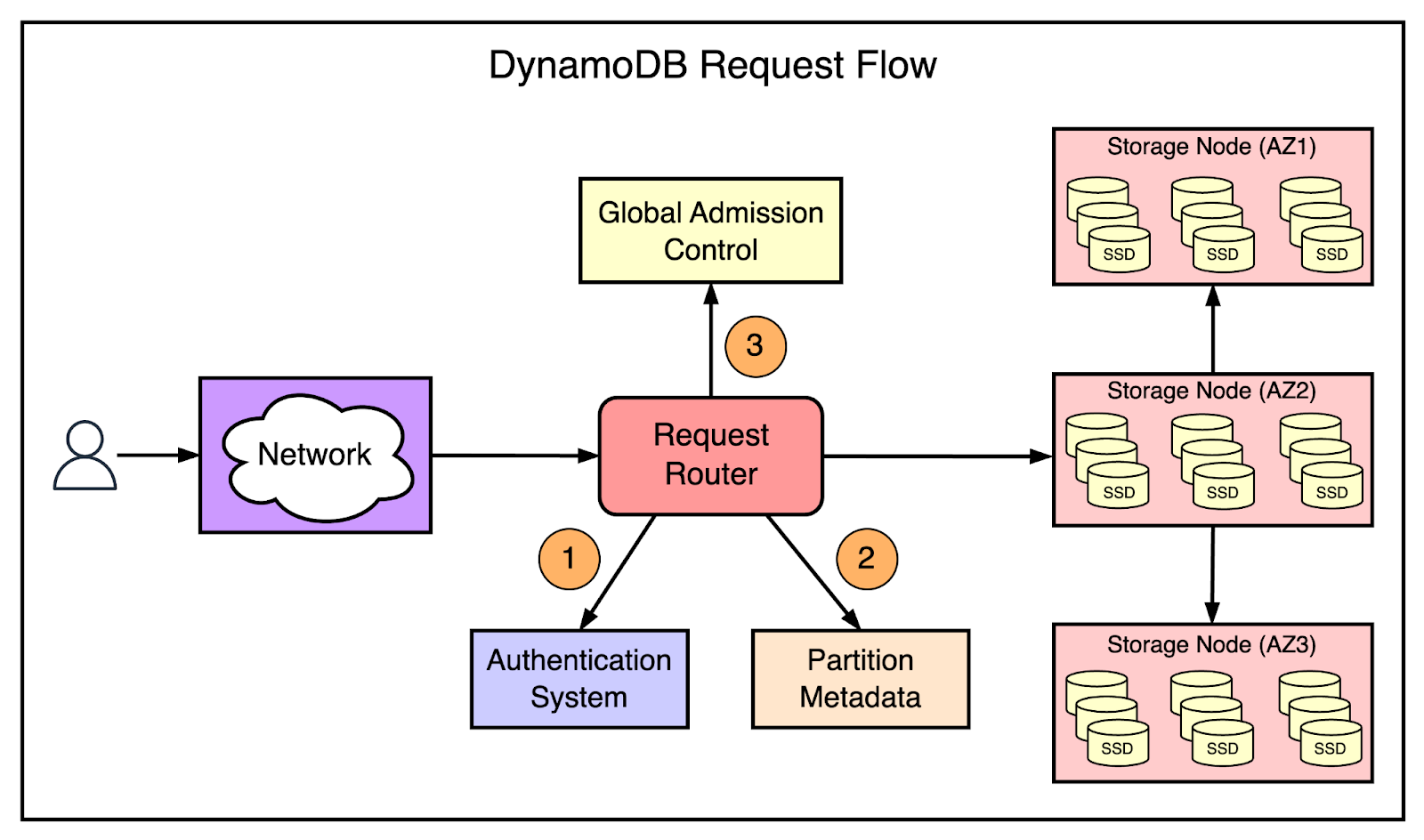
Micro-service architecture
 image
image
DynamoDB employs a micro-service architecture, some of the key micro-services are mentioned below:
- Metadata service - The metadata service stores routing information about the tables, indexes, and replication groups for keys for a given table or index.
- Request Routing Service - The request routing service is responsible for authorizing, authenticating, and routing each request to the appropriate server.
- Storage nodes - The storage service is responsible for storing customer data on a fleet of storage nodes. Each of the storage nodes hosts many replicas of different partitions.
- Autoadmin service - All resource creation, update, and data definition requests are routed to the autoadmin service.
mermaid
Autoadmin Service
This service is the Central Nervous System of DynamoDB. It takes care of fleet health, partition health (replacing unhealthy storage nodes with healthy ones), execution of control plane requests (like creation of tables, indexes, management of compute units etc.)
Metadata Service
Metadata service holds the most critical mapping of partitions of table, key-range of each partition and storage node of each partition. Request Routing Service uses Metadata service to know which node to redirect the request to. But because the metadata rarely changes, DynamoDB decided to cache the routing data received from Metadata service locally. But this posed a significant problem. If, for any reason, the router service reboots, all the cached data will be lost and all the traffic will be routed to the metadata service resulting in a probable outage. To prevent this, amazon built an in memory distributed data source called MemDS which is optimized for range queries.
mermaid
But even with MemDS if the router service reboots for any reason, we have the same problem, of MemDS experiencing more traffic than it scaled to handle. To solve this problem, DynamoDB ensures MemDS is always scaled to handle all the incoming traffic. This is ensured by sending an asynchronous request to the MemDS whenever a request is received by the Routing service, irrespective of whether the routing information was found in local cache or not. We don't process the response of MemDS (if the info was found in local cache), we send the request to make sure MemDS is always scaled enough to handle 100% of the traffic. This ensures that there are no cascading failures.
Storage Admission Control
Admission control ensures that storage nodes are not overloaded with more requests than they can handle. As each storage node can host multiple partitions, its the admission controls job to make sure each partition does not receive more requests than what the user has provisioned.
On top of this, its the job of autoadmin service to ensure that one storage node is never assigned partitions whose cumulative limit is greater than the total limit of the storage node (usually the physical limit of the storage node instance).
But how do we know whats the limit of a partition? i.e. How many requests is a partition supposed to receive? We don't. So we assume on Day 0, that each key is equally likely to be accessed, therefore it splits the provisioned Read Capacity Units (RCUs) and Write Capacity Units (WCUs) equally among all the partitions.
Let's assume we have provisioned our table with 300 WCUs and 900 RCUs, and DynamoDB initially creates 3 partitions. This means, each partition will have 100 WCUs and 300 RCUs. Now if any one of our partition starts running hot, DynamoDB will split it. So now each of out partition will have 75 WCUs and 225 RCUs. Wait... so on experiencing more traffic we reduced the provisioned units on that partition? That does not make sense. This problem is called throughput dilution.
Handling throughput dilution
Burst Capacity
We already know that not all partitions use all of their provisioned capacity. So we put this knowledge to use and we borrow capacity from partitions that are not using their capacity and temporarily give it to the partition that needs it.
DynamoDB internally uses Token Bucket Algorithm to keep track of provisioned units. Every storage nodes has a global token bucket and within the storage node every partition within has two token buckets, allocated and burst.
For any incoming request,
- If allocated bucket of the partition has enough tokens, reduce and allow.
- Otherwise, if burst bucket of the partition has enough tokens and allocated bucket of the node have enough tokens, reduce from both and allow.
Adaptive Capacity
Burst capacity is for short lived spikes in traffic, but for long lived shifts in traffic, the autoadmin service automatically dynamically distributes the throughput based on the traffic received by each partition.
Global Admission Control
Global Admission Control (GAC) is a table-level load regulation mechanism in DynamoDB that determines whether an incoming request should be accepted or rejected based on the table’s overall provisioned throughput and current system load.
It ensures that:
- The total request rate does not exceed the table’s provisioned capacity.
- The system does not become overloaded under sudden traffic spikes.
- Excess requests are rejected early, before consuming significant internal resources.
DynamoDB’s architecture is less about scaling infinitely and more about scaling predictably.
The system is designed not just to handle high traffic, but to survive skew, failure, misconfiguration, and sudden shifts in workload.
The real engineering challenge isn’t distributing data — it’s preventing small imbalances from becoming cascading outages. DynamoDB’s design shows how deeply that problem has been thought through.